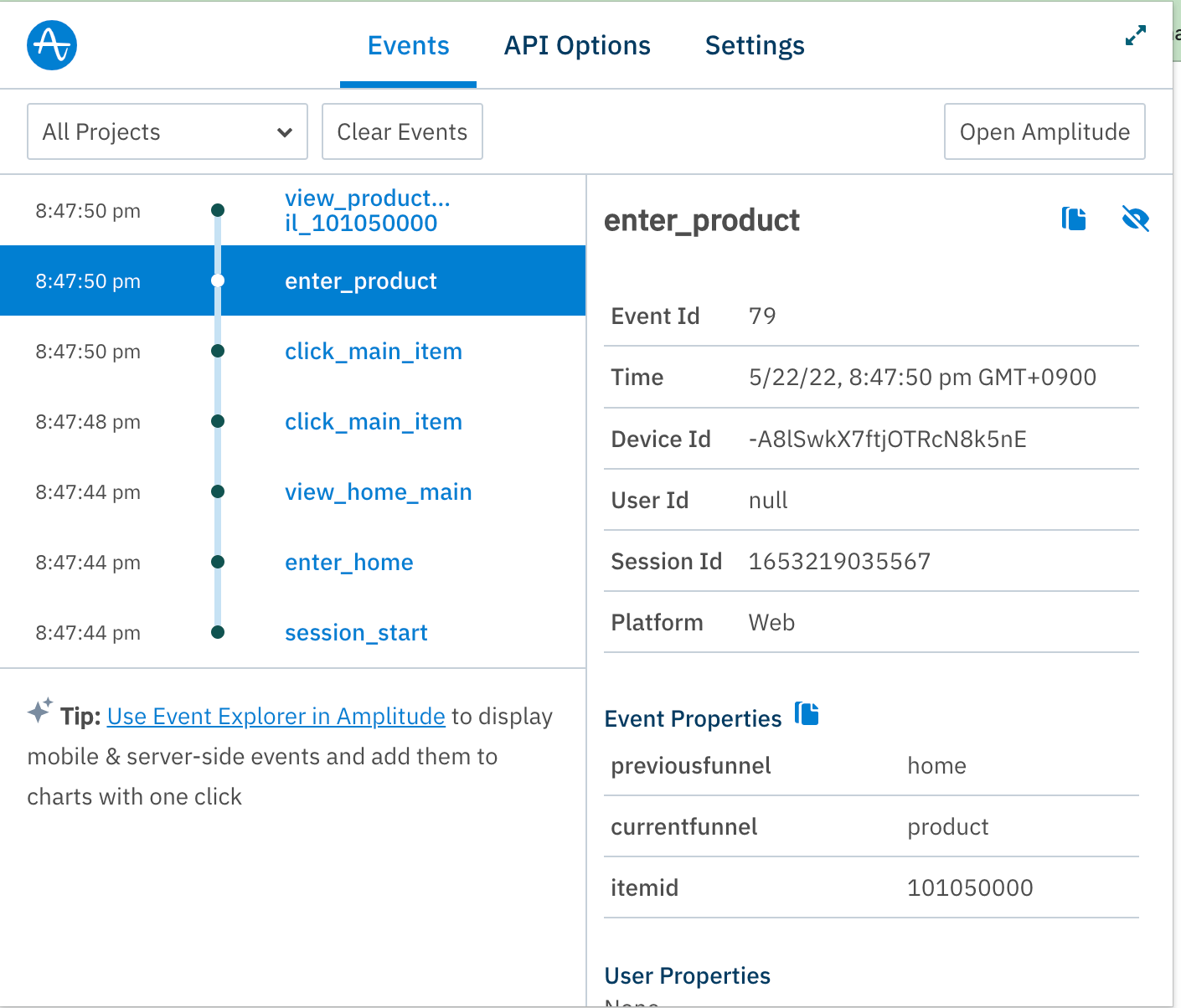
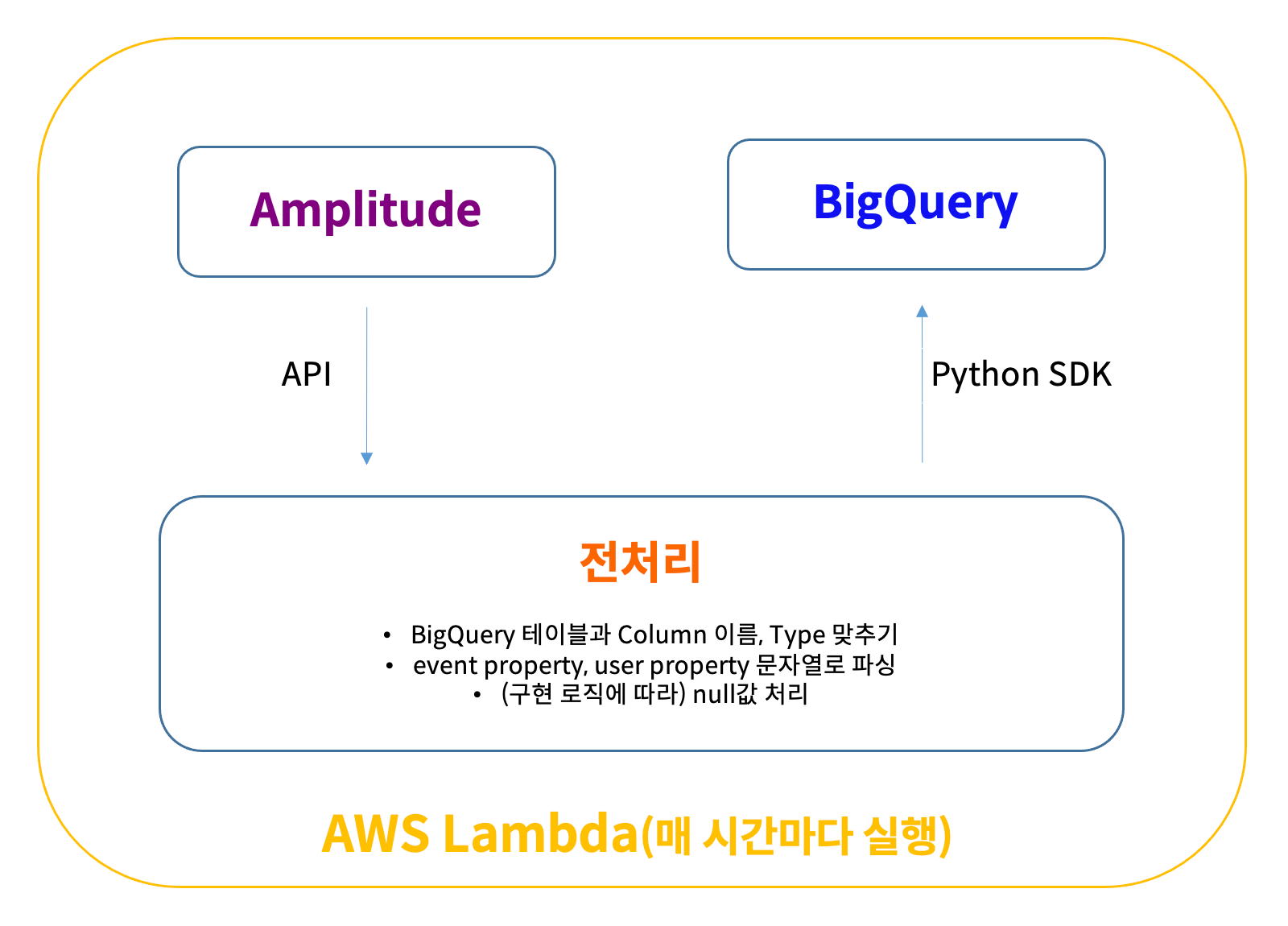
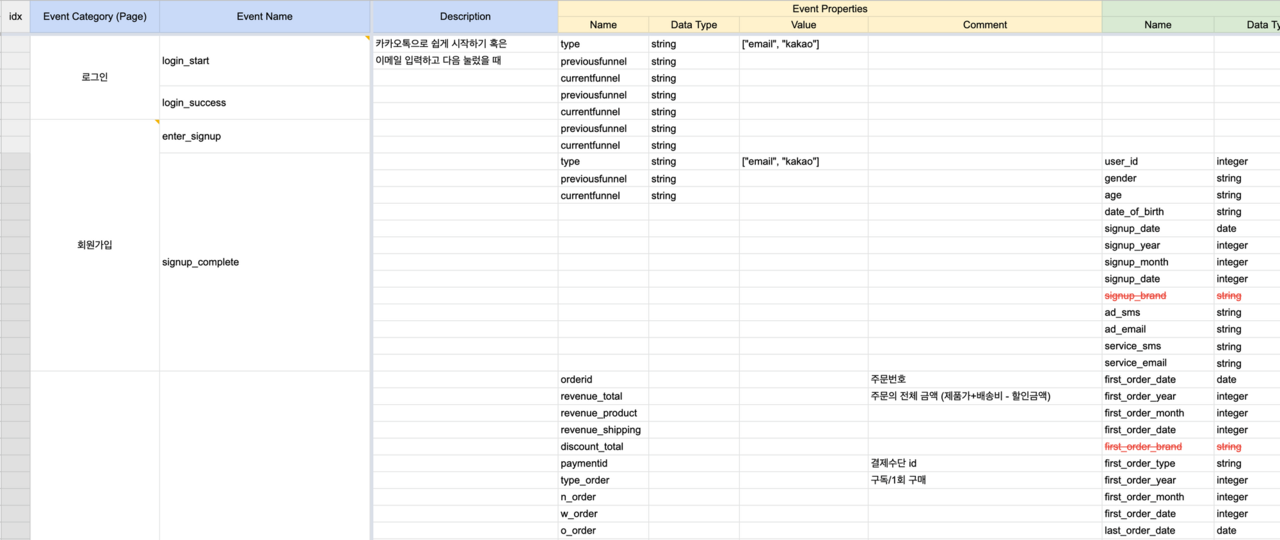
추가 과금이 필요했던 두 가지 시도
1. Snowflake에 저장한 후, BigQuery로 옮기기
Amplitude에서 제공하는 파이프라인으로 Snowflake에 데이터를 옮깁니다. 그리고 기존에 사용하고 있던 ETL 툴인 Stitch를 통해 Snowflake에서 BigQuery로 데이터를 전송하면 BigQuery에 웹 이벤트 데이터를 쌓을 수 있습니다. 그러나 이 방식은 DW인 Snowflake를 사용하는 데 적지 않은 과금이 필요했고, Stitch가 이 데이터를 추가로 옮겨야 하므로 이전보다 더 비싼 요금제를 선택해야 했습니다.
2. Google Cloud Storage(이하 GCS)에 저장한 후, BigQuery에서 GCS에 있는 데이터로 테이블 생성하기
Amplitude에서 제공하는 파이프라인으로 GCS에 데이터를 옮깁니다. 그 후 BigQuery에서 테이블을 하나 만들고, 이 테이블이 GCS 데이터를 가져오도록 설정해두는 방법이 있습니다. 하지만 이 방식 역시 새로운 데이터베이스 시스템을 사용하기 때문에 추가 과금이 발생합니다. 또한, 이벤트의 모든 컬럼 값을 다 저장하면 용량이 커지기 때문에 필요한 컬럼만 저장하기 위해서 직접 파이프라인을 개발하는 것이 낫겠다고 판단했습니다. GCS에 있는 데이터를 BigQuery로 옮기는 과정에서 알 수 없는 에러가 계속 발생하기도 해서 더 시도하지 않았습니다.
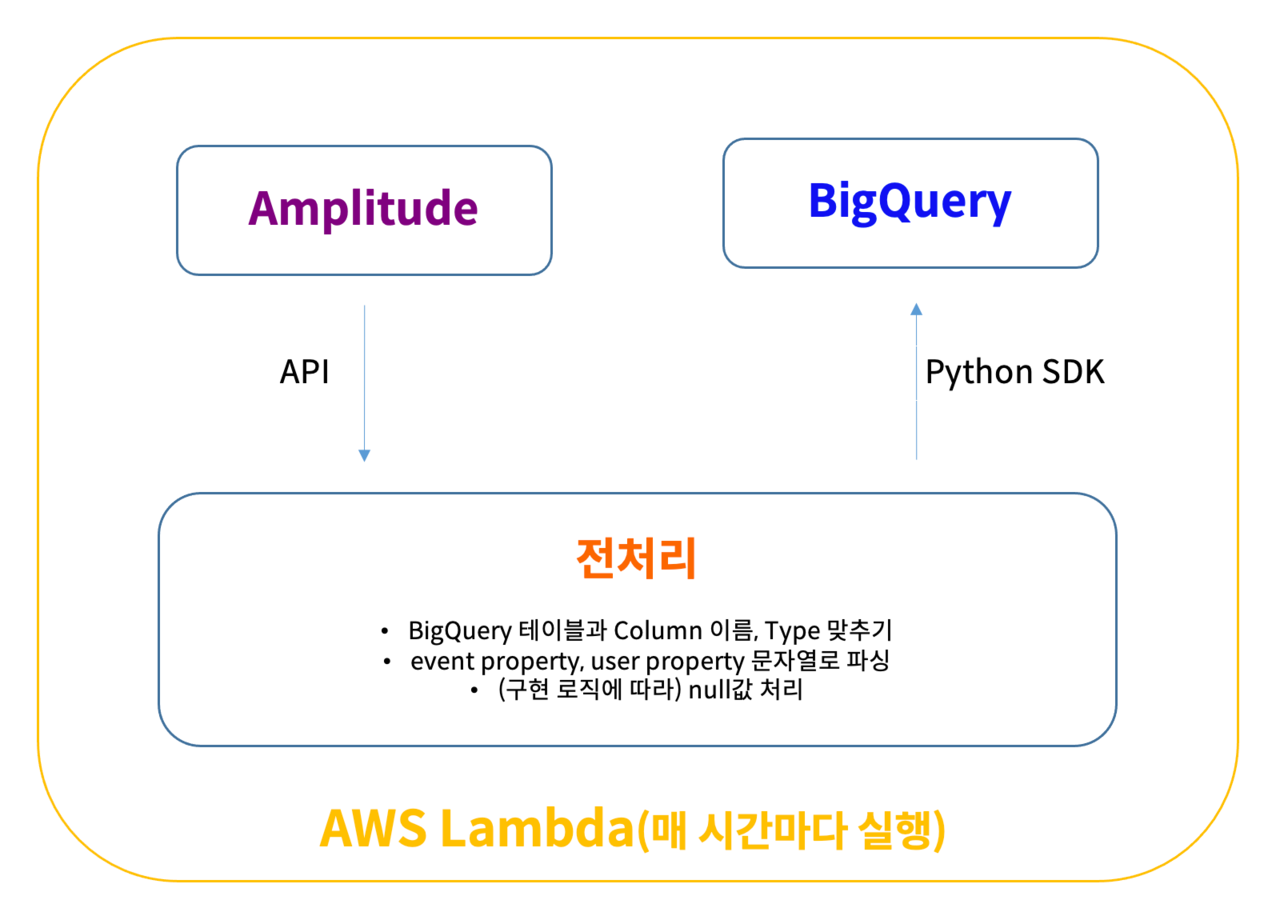
불필요한 과금이 발생하는 방식 대신, 와이즐리컴퍼니는 Amplitude와 BigQuery의 API를 이용해 작은 데이터 파이프라인을 직접 만들었습니다. Amplitude에서 API로 raw data를 받아오고, 그것을 BigQuery에 저장하는 로직을 서버에서 주기적으로 실행시키는 것입니다. AWS Lambda의 프리 티어를 적절히 이용하면 과금 또한 없거나 적고, BigQuery에 저장하는 연산에만 비용을 지불하면 됩니다. 와이즐리컴퍼니는 현재 Lambda를 사용해 구현한 파이프라인이 매시간 자동으로 돌아가도록 하고 있습니다.